Lessons Learnt for Machine Learning VFX
Ryan Laney & Teus Media
Ryan Laney has a long history of using technology to support storytelling for films and special interest projects. He recently completed work on the documentary feature Welcome to Chechnya where he worked with the filmmakers to develop and employ a novel technique to protect identities. He founded Teus Media to continue these efforts, building tools for journalists and documentary filmmakers. As a result of his work and achievements, this week Laney joined the Academy as one of its newest members.
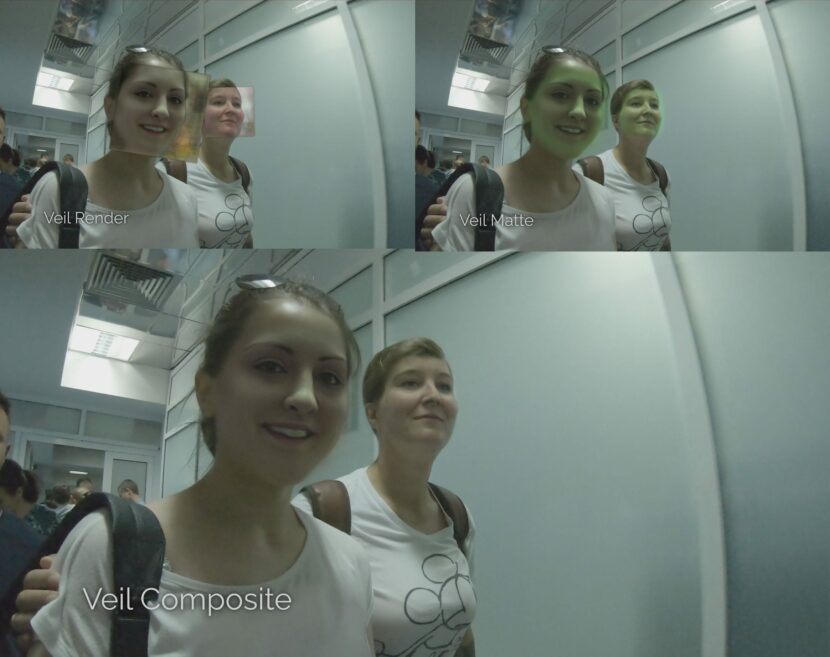
Welcome to Chechnya became the first documentary to ever be shortlisted for the Visual Effects Oscar. The film was directed by David France (2012’s Oscar nominee, How to Survive a Plague) and it chronicles violence against the LGBT population in the Russian republic of Chechnya. Because being exposed as gay is punishable, 23 individuals or witnesses seen in the film had their faces masked in post-production with the faces of volunteers or actors, in 480 shots. In total over 100 screen minutes were produced, with often times multiple people being treated in the same shot.
Getting Involved
Laney’s career includes working at ILM, Digital Domain, and Sony, he has worked on teams developing tools, workflows, and effects for summer blockbusters including Harry Potter, Green Lantern, and Spider-Man. More recently he has been designing software to help remove technical limitations for filmmakers and storytellers.
Laney and his team first got involved to help with about an hour of rotoscoping the filmmakers believed they needed to do to apply some sort of treatment onto the faces of the witnesses. Laney’s team experimented with Style Transfer to do this directly via neural rendering. This approach became the nucleus of the digital veil or ‘censor veil’ technique that the team would end up using in the film.
Transferring the style from one image onto another can be considered a problem of separating separate image content from style. The approach was first introduced in a paper Image Style Transfer Using Convolutional Neural Networks, in 2016. This process was made popular by showing an image inferred in a range of different painting styles. In this case, it is easy to understand that the content remains the same but the style of its visualization changes. Laney initially explored this as a way to keep the same expression of the witness but change the look of their face. In their tests, they tried rendering the new face in an abstracted cartoon style. The problem was that a caricature of a person actually does not mask their identity well. You still know who someone is from a cartoon version of them. It also could be argued that this version may not have been in keeping with the serious nature of the documentary.

The solution was to swap the witness’s face with that of an actual actor. The principle of such a transfer is a correlation between two faces. Data sets of both faces are required, ie. both the witness and the actor, and whose face the audience will only ever see.

This application is different from many ‘deepfake’ projects or neural renders where the face of a famous person is applied to an actor. Specifically, in the typical ‘deepfakes’ approach, the face that is being replaced is filmed under control conditions and the ‘famous’ face is inferred from a compile of images and clips scrapped from the internet. In Welcome to Chechnya the reverse is true. The witnesses and their base footage was shot in documentary style without VFX control or special controlled lighting etc, and the sampled face of the volunteers or actors were able to be shot in controlled conditions.
Shooting the right training data, the right way:
Laney and the team shot the actors under controlled conditions. First, they tested shooting the actors on a white screen but then they moved to film the actors on blue screen. This was because they found by pre-comping the training footage of the actor over an approximately matching background helped the process.

The rule of thumb was that as soon as a person’s head turns away from looking directly to the camera, and their far side ear is no longer visible, it was worth compositing the training data actor over a relevant background. “As they turn and then you have skin directly over the background, that is where all this extra work comes into play”, explains Laney. “Especially when the head turns even more and their eye or eyelash comes over the background,.. and this is where you will see missing in most examples of Neural Networks.” The problem stems from a first-order gradient issue, as even with the crop, half the frame is background either lighter or darker than their skin color. “If I have shot my face double over say white, and I am working with a shot over a dark background, for example, if they are heavily front-lit, then the gradient would be backwards and your face actually flips (horizontal).” To find the correct background the team took effectively an average of the real background.
The right training footage matters a lot.
As a general rule, Laney shot a lot of material to be used as training material but ‘more does not equal better’ when it comes to neural rendering. Laney found that a key step was focusing on selecting the right training clips. From the large library of possible training material for any witness face replacement, only a carefully curated sub-set was used. The process deployed several machine learning tools to keep track of the training data and automatically produce a set of frames/clips based on matching head angle, color temperature, and lighting. Naturally, there was person-specific training, but also often sequence-specific and even shot-specific training data. pulled from the master database using a NumPy (Euclidean) distance, ‘big table’ lookup approach based on the data set’s face encoding. The face encoding was based on face angle and expression.

A range of motion (ROM) and pangrams were better than trying to get the actors to match emotion.
The training data system had levels of categorized data. For each witness, there were actor-specific groupings of training data, and then there were often scene-specific categories and even shot-specific groupings. In other words, the frames used to train on could vary on a shot-by-shot basis, depending on the raw lighting and camera position of the documentary footage.
When filming the actors the team encouraged the actor to move their heads, perhaps in a circular motion, not so fast there is motion blur but certainly, the team did not want the actors to remain still as they were filmed. One important aspect Laney found was to ask the actors to also tilt their heads side to side. “We get a whole range of great lighting variation as someone twists their head, and that lighting variation is really important, and it just doesn’t matter that their head is not vertical in frame.”
It was not key to emote appropriately in the training session. In capturing the training data, Laney did not find it useful to try and get the actors to specifically act out any particular performance, or record them acting any specific emotions. Rather a range of motion, expressions, and spoke dialogue was ideal, and specialist ML programs solved the rest, by selecting the most likely useful subset from all the possible footage and image options. This used a separate pre-face swapping ML program that just focused on training data preparation.

One needs to be careful to not bias the training data Each actor was filmed with 9 cameras placed around them to capture multiple angles of the same performance. This was done with some thought that photogrammetry might be needed. The project never did use the camera’s multiple clips for that purpose. During the setup of the cameras, the actual shutter control could not be controlled synchronously. As a result Ryan just let the cameras run and they did not cut between takes. This resulting in training footage of both the deliberate takes and the random in-between recording of the actors talking to the director, who was off to one side. The result was that the training data as a whole had a bias to one side of the actor’s face, (the side shown to the cameras when the actor turned to talk to the director). Ryan points out this is exactly the sort of unbalanced or training data bias that one needs to avoid.
In Welcome to Chechnya, they avoided this by using their ML pre-training data sorting. The team could have manually edited all the footage, but there was a huge amount. Instead of editing and then labeling all the training data, Laney wrote a subsystem to facial encode the documentary witness footage and then find similar takes in the training data – thus the training data sets were built up from the ML pre-pass take selection process. This led to tight coupling and allowed strong attention to the training data that would be used.

Matching lighting
Before the training even starts, the detailed pre-processing works to match head position, expression, and lighting between the actor and the witness. Not only was it important to have training footage with a good range of lighting directions, side, top, etc, but the process also worked best when the color temperature of the footage was able to be matched. It is important to note, one does not need to have perfect matches, but the better the training data matches the more likely the end results will succeed.
Auto-white balancing (auto-exposure) was used on many of the documentary cameras. To work with this range of footage, the pipeline solution was to find the principal colors in the shot using K-means clustering and then normalize the faces before running the veiling process. This helped get the best skin tone match for the two people on either side of the effect (inference).
k-means clustering is a method of vector quantization, originally from signal processing, that aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean (~average), serving as the basic core ‘example’ or prototype of the cluster.

Body types – the fullness of cheeks were more important than chins
Ryan found that chins were easy to morph, so in casting the actors he found having the right fullness around the cheek area was more important than the jawline. The actors did not need to look the same but it helped enormously to have the temples and cheeks similar. “The thing about jaws is that they are easy to warp, .. it is easier to move a jaw than take 30 pounds off their face.”
While not a body type issue, the lenses that shoot the faces affect the perception of the faces relative proportions. In the extreme case, a wide-angle lens will make a nose seem much larger relative to the eyes than a 200mm lens would filming the same face.
A key blend place is the hairline and in particular the temples. People have very different hairlines, and getting the hair transition line on the side of the head, especially true for short-haired witnesses, proved a key aspect of selling a blended face.

The witness footage was also pre-processed. As the witness footage was shot ‘in the wild’ it has a lot of naturally occurring issues and visual issues that would cause ML problems. Some backgrounds could ruin face tracking and inference. In particular, if the background was varying high contrast, it could be a problem, such as when one of the witnesses was filmed walking past a black and white fence. The majority of the face worked well, but the nose and edge line of the face was unstable. To solve this, the varying background was averaged and the witness footage pre-comped to produce a more even tone or lower frequency background. This was then reversed once the face was solved, back to the original background.
Tracking and partitioning
All the footage was tracked and for shots with multiple witnesses in a shot, where all their faces had to be swapped, the pipeline relied on ML tracking each actor. AlexNet was used to track multiple faces in the same shot. AlexNet is the name of a fast GPU convolutional neural network (CNN), designed by Alex Krizhevsky for object recognition/person identification. AlexNet is an incredibly powerful CNN capable of achieving high accuracies on very challenging datasets. However, it does not work well on side profile shots. For those shots a simple optical flow was used to predict where a person would be in the next frame, “it was one of those solutions that I just hacked together, to be honest,” Laney jokes.
The Future
Laney has a vision for the future, “I like the idea of not just building one (ML) model to rule them all, I want people to understand that the Neural Network is like a compositing tool and Tensorflow is like Nuke. So if I want to do this thing, then I can use this general-purpose tool, but I can use it in different ways. To continue with the analogy of Nuke, most compositors, only use 5 or 10 nodes regularly but they use them in different ways. And they can combine them in special ways and create their own nodes. But I feel there has to soon be a Nuke-like tool for building Networks to do special-purpose (ML) things.” Laney points to how Houdini built a node-based graph tool, for simulations. Sidefx does not build the simulation, they build the network that the information will flow through.
Teus Media makes face replacements and their censor veil available on a budget hitherto unheard of. Laney specifically wants to help documentary filmmakers and has already helped a huge range of people tackling many social and human rights projects.
Ryan Laney is also talking at DigiPro and Pipeline conference later this month.
Note in this article, only one witness, Maxim Lapunov, is shown untreated, as he went public in the film. No other witness’s identity is disclosed here.
Article content ref by: www.fxguide.com/